
最近 NoSQL をいくつか使っていて、グラフDBの neo4j が面白かった。
グラフDBの特徴は、RDBでは難しい関連性の検索を得意としていることで、実際に経路検索やリコメンドエンジンなどで使われているようです。面白かったのは、RDBでは難しい、クレジットカードの詐欺検知などでも使えるということで、人間がロジックを作るのが苦手な部分が得意という面で、機械学習とかに通ずる楽しさがありそう。
初心者なので、用語の使い方がおかしかったり、クソコードだったりするかもしれませんが、その点はご容赦ください。。
試しに、電車の経路検索を作ってみます。
OSX で簡単に試せます。
準備
install
$ brew install neo4j
run
$ neo4j start
とやると background で立ち上がるのですが、何度やっても立ち上がらないことがあり、その場合は、
$ neo4j console
とやるとフォアグラウンドで、確実に立ち上がります。(謎)
reset
色々やっててデータを全消去したくなった時は、バージョンなどを読み替えて下記のコマンドで乱暴に消せます。 実行時は色々なことに注意してください!
$ neo4j stop
$ rm -rf /usr/local/Cellar/neo4j/3.0.4/libexec/data/databases/graph.db
$ neo4j start
ブラウザで見る
http://localhost:7474/
にアクセスすると、親切そうな画面が現れます。上のところにコマンド入れると色々実行できます。
↓のシェルは、; で区切って複数実行出来るのですが、ブラウザで見る場合は1回の実行で必ず1回しか実行できないので、同じ変数が2回現れたりするとエラーなので注意です。
シェルで見る
$ neo4j-shell
で立ち上がります。
ブラウザで見た時に、チュートリアルで俳優と映画と役のサンプルデータをロードして、試せるようになっているので、それをやるとなんとなく分かります。
簡単な概念の説明
neo4j は完全にスキーマレスです。INDEX を作成することは出来ますが、INDEX のスキーマも決めなくて大丈夫なようです。
- ノード
- リレーション
という登場人物がいます。言葉から連想される通りに、ノードが実際のモノを表していて、リレーションはノードとノードをつなぐ関連性を表します。どちらも、ラベル(プログラミングでいうところのクラスと同じと思ってOKそう)とプロパティ(これはそのままの意味)を持てます。
これは書籍からの受け売りですが、どちらも抽象的なので、RDBのように事前に設計することは難しく、データ構造は試行錯誤しながらトライアンドエラーで決めていくもののようです。
例えば、今やろうとしている路線検索に当てはめると、
- ノード が 駅
- リレーション が 線路
というパターンもありそうですが、普通、急行、特急でそれぞれ止まる駅が異なるので、「駅Aから駅Bに1つ進む」という情報をリレーションとして持つという方針にしてみます。
- ノード が 駅(ラベルは
Station) で、ここではプロパティとして駅名(name) - リレーション が 経路(ラベルは
Section)で、ここではプロパティとして種別(kind),所要時間(minutes)※種別は、普通・急行・特急を表す
となります。
他のパターンとしては、経路を NormalSection (各停の経路) と ExpressSection (急行の経路) と分けたり、全駅間を Relation として持つなどもあると思います。とりあえず今回は、↑でやってみました。
経路検索をしてみる
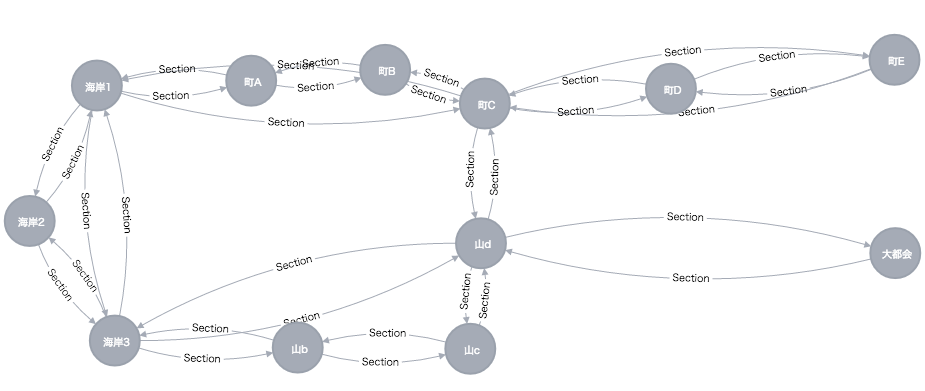
この後は、空想の3路線をでっち上げて、路線検索を作ってみます。
データ定義

- 赤路線、黄路線、青路線の3路線があります。
- どの路線も必ず端から端までしか行かないとします。
- 2つ以上の路線が交わる駅では乗り換えが出来ます。
- 種別は、各駅停車と急行の2種類があります。
- 各駅停車は、全部の駅に停車します。
- 急行は、背景が黒い駅のみに止まります。
- 線路に書いてある数字は、駅間の所要時間です。
- 曲線で書いてあるところは、急行で移動した場合の所要時間です。
という具合です。
はじめてのノード
ブラウザでもシェルでも良いので、コマンドが打てる状態にして、下記を打ちます。
CREATE (station:Station {name: '海岸1'});
すると、
Added 1 label, created 1 node, set 1 properties, statement executed in 342 ms.
成功したっぽいメッセージが出たと思います。
その状態で
MATCH (n) RETURN n;
とすると、丸が1個だけ画面上に出てきたと思います。これがノードです。
はじめてのリレーション
リレーションは、ノード間の関係なので、ノードをもう1個作ります。
CREATE (station:Station {name: '海岸2'});
ノードを2個指定して、リレーションを作ります。
MATCH (from:Station { name: '海岸1' })
MATCH (dest:Station { name: '海岸2' })
CREATE (from)-[:Section{minutes:3, kind:'各停'}]->(dest);
MATCH で変数に束縛するのは、Elixir っぽいです。(最近使い始めた)
もう一度先ほどのコマンドを実行します。
この意味は、全てにマッチする n を返す。なので全部の Nodes が返ります。
MATCH (n) RETURN n;
こんな感じになりました。

MERGE
CREATE を使うと、同じものが何個も出来てしまうのですが、代わりに MERGE を使うと、同じ属性のものがあったらそれを上書きします。
MERGE (station:Station {name: '海岸1'});
とすると
(no changes, no rows)
となって、何も起きません。
なので、以後 MERGE で書きます。(但しこれが良い方法なのかは不明)
データ作成
諸々のデータを登録します。
MATCH (n) RETURN n;
とすると、ごちゃっと出るのですが、ドラッグ&ドロップしてなんとなく並べると、先ほどの図のようになりました!
この後は、経路を検索してみます。
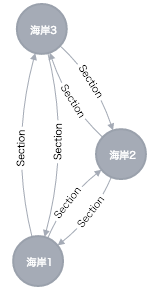
経路検索
とりあえず、2駅先までの経路情報を出してみます。
MATCH (from:Station {name: "海岸1"}), (to:Station {name: "海岸3"}), path=((from)-[:Section*1..2]->(to))
RETURN from, to, path
Sectionのところでは、1個から2個までのリレーションを挟む経路を指定しています。
海岸1から海岸3に行くには、各停で2個進むか、急行で1個進めば良いということがわかります。
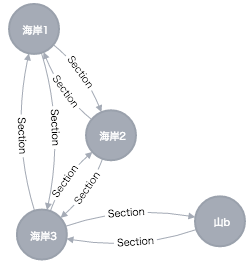
次に、REDUCEを使って所要時間を算出してみます。
MATCH (from:Station {name: "海岸1"}), (to:Station {name: "山b"}), path=((from)-[section:Section*1..3]->(to))
RETURN from, to,path,
REDUCE(totalMinutes = 0, s in section | totalMinutes + s.minutes) as 所要時間
ORDER BY 所要時間
LIMIT 10
このような出力になりますが、何やらいっぱい出てます。
Rowsを見てみると、所要時間が表示されて所要時間順に並んでいることがわかります。
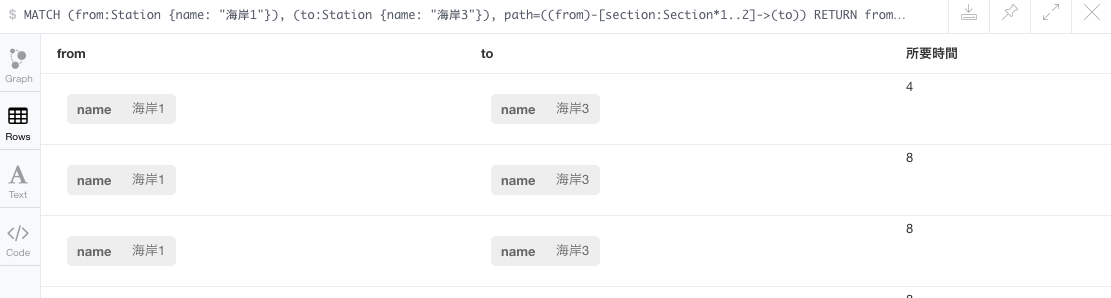
いい感じですね。
MATCH (from:Station {name: "海岸1"}), (to:Station {name: "山b"}), path=((from)-[section:Section*1..3]->(to))
WITH
EXTRACT(section in rels(path) | section.kind) as 経路,
EXTRACT(station in nodes(path) | station.name) as 乗り換え駅,
REDUCE(totalMinutes = 0, s in section | totalMinutes + s.minutes) as 所要時間
RETURN 所要時間, 乗り換え駅, 経路
ORDER BY 所要時間
LIMIT 10;
駅と区間をテキストで並べてみます。本当は 海岸1->急行->海岸3->各停->山b みたいに表示したが、まだそのやり方が分かっていない…。

最短経路検索
MATCH (from:Station {name: "海岸1"}), (to:Station {name: "大都会"}), path=allShortestPaths ((from)-[section:Section*]->(to))
WITH
EXTRACT(section in rels(path) | section.kind) as 経路,
EXTRACT(station in nodes(path) | station.name) as 乗り換え駅,
REDUCE(totalMinutes = 0, s in section | totalMinutes + s.minutes) as 所要時間,
path
RETURN 所要時間, 乗り換え駅, 経路, path
ORDER BY 所要時間
LIMIT 10;
allShortestPaths で、最短経路となったものの結果一覧が返ってきます。町側を経由していくのと、海→山と経由していく2つのルートが出ています。shortestPath にすると最短のものが返ってきます。
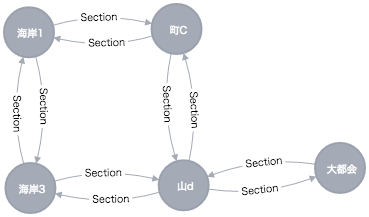
この例だと、町を経由していくほうが早いみたいです。

トラブル時の迂回経路の検索
山c -> 町E へ行くという経路を考えます。通常時は、山c -> 山d -> 町C -> 町D -> 町E と進むのが早いはずです。
今、町C と 山d の間で何らかのトラブルがあり、その区間の所要時間が120分になってしまいました!そのようなデータを作ります。
MATCH (from:Station {name: "山c"}),(to:Station {name: "町E"}), path=((from)-[section:Section*1..9]->(to))
WITH
EXTRACT(section in rels(path) | section.kind) as 経路,
EXTRACT(station in nodes(path) | station.name) as 乗り換え駅,
REDUCE(totalMinutes = 0, s in section | totalMinutes + s.minutes) as 所要時間
RETURN 所要時間, 乗り換え駅, 経路
ORDER BY 所要時間
LIMIT 10;
すると、下記のようなデータが返って来ます。

山d -> 町C という部分を通ってしまうと120分加算されてしまうので、海岸の方を迂回していく方が早いということが分かります。
一番早いのは、 海岸3 まで各停で行って、その後は急行を乗り継ぐパターンです。
二番目に早いのは、一旦 山d まで各停で行って、そこから急行に乗り 海岸1 を経由して行くパターンです。
遅延データをリアルタイムにDBに反映していけば、その時々で最短のルートを検索することが出来て便利そうです。